AI & ML

What is Applied’s Self-Driving System?
Our team has brought together the best minds from top autonomy programs like Waymo and Cruise to build autonomy from the ground up - focusing on solid foundations for scaling data and compute instead of fighting over resources or maintaining legacy infrastructure.
Who are we building for?

Trucking

ADAS

Off-road
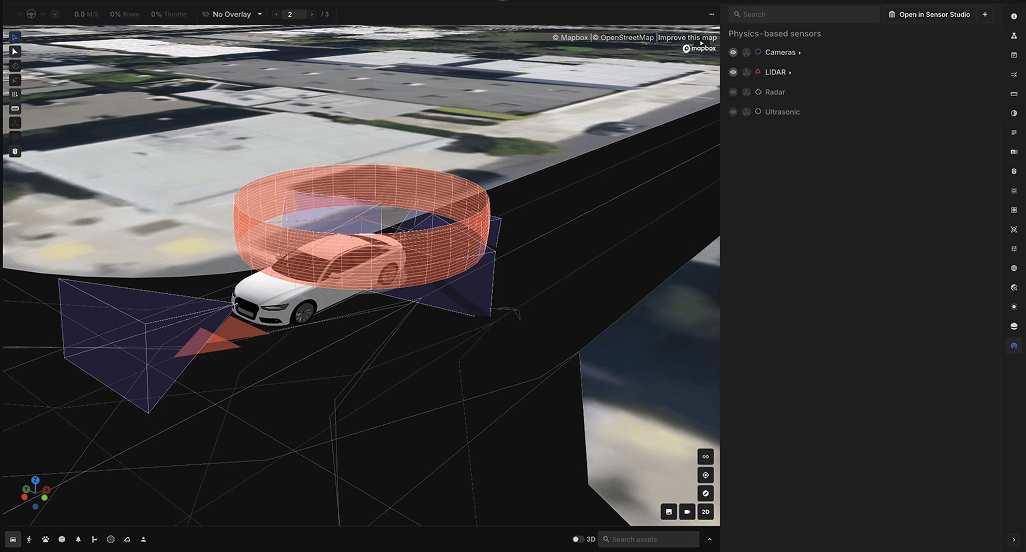
Perception

Premkumar Natarajan
Engineering Manager
Nuro, Embark
Learn the strongest representation of the world from diverse sensor modalities, supporting both on-board and off-board use-cases. Build world models to understand the autonomous vehicle, its environment and other agents, with large self-supervised techniques. Use the latest foundational models, reconstruction, and diffusion techniques for a modern take on perception and autolabeling.
What makes perception at Applied different?
What problems do Perception Engineers solve?
What does customer interaction look like?
How is working in Japan different from working within the US?
How do you make sure the perception model works with different sensor modalities?
Behavior & Machine Learning

Brian Zhang
Engineering Manager
Waymo, AutoX
We are building the next generation of autonomous driving by developing intelligent policies that don't just react to the present, but actively reason about future scenarios and predict how other agents will behave on the road. We're tackling the challenge of scaling these sophisticated behaviors to massive unlabeled datasets while embedding critical safety guardrails directly into our planning algorithms. Through continuous refinement with real-world data and closed-loop simulations, we're building robust autonomy solutions that perform reliably across diverse environments - from busy urban streets to challenging off-road terrain.
Why do we use ML for behavior?
What’s Applied’s unique advantage in e2e driving?
What are the biggest challenges in productionizing the latest e2e research?
What kind of backgrounds or skill sets thrive on the Behavior ML team?
Planning & Controls

Skylar Wei
Software Engineer
CalTech PhD, NAVAIR
Whether it’s an 18-wheeler, a mining haul truck, or an offroad vehicle, the principles of motion control remain the same: move safely, efficiently, and predictably. We develop planning and control stacks that score and validate learned trajectories, and translate them into actuation commands to ensure safe, efficient, and reliable operation in dynamic environments.
What are the biggest challenges building for off-road vs on-road?
How do we reason about traversability in uncertain or partially observed terrain?
How do you evaluate a “good” plan when there’s no single correct answer off-road?
How do you adapt control strategies when terrain and dynamics change rapidly and unpredictably?
What’s one area where off-road autonomy has taught you to think differently than traditional robotics?
What excites you most about solving autonomy in unstructured environments?
Data & Evaluation

Simone Gelmini
Technical Lead
Cruise, MIT
Our Data and Evaluation team drives the continuous improvement that makes autonomous systems safer and smarter. We build scalable pipelines to turn raw sensor data into high-quality training and validation sets, and develop metrics and tools that help ML engineers measure model performance in both simulation and real-world driving. Working closely with engineering teams, we create feedback loops that turn every mile and model update into actionable insights. This is where data science fuels autonomy through rigorous evaluation and continuous learning from real experience.
Why Applied?
Why Evaluation?
How do you define and measure success for autonomous behavior in complex, real-world scenarios?
What are the biggest challenges in creating high-quality metrics and datasets that can reflect real-world operating conditions?
What’s something surprising you've learned from developing metrics and analyzing failure cases?
What is Data & ML Infrastructure at Applied?
We are the backbone that makes modern autonomy possible - from ingesting sensor data off vehicles to training models. Our team has assembled experts from leading tech companies and autonomy programs who understand that the difference between a research prototype and a deployed autonomous system lies in rock-solid infrastructure. We embrace cutting-edge distributed systems and ML operations to create platforms that scale effortlessly while maintaining the reliability that safety-critical systems demand.
Who are we building for?

Internal Teams

External Teams
Data Engine
Build the complete data flywheel where model performance drives intelligent curation to create diverse, high-quality datasets. Create robust pipelines for collection, ingestion, processing, labeling, curation, and mining that handle hundreds of petabytes. Design systems that continuously improve by identifying gaps in model performance and automatically sourcing the right data to address them, enabling rapid iteration on perception and behavior models.
What makes our Data Engine stand out:
- Built for autonomy: Supports perception, prediction, planning, and full-stack programs across trucks, cars, off-road, and research.
- Proven at scale: Powers thousands of fleet hours with end-to-end data collection, labeling, training, and evaluation.
- Global and flexible: Cloud-agnostic, production-ready, and deployed across the US, Japan, and EU.
- Multi-modal: Handles images, LiDAR, radar, audio, and more—hundreds of petabytes across billions of records.
- Model-driven: Uses performance insights to target data gaps and accelerate iteration.
Data & ML Infrastructure
Our Data & ML Infrastructure team builds the compute backbone that powers next-generation autonomy models from training to deployment. We design platforms that orchestrate thousands of GPUs, enable rapid model iteration, and serve models at production scale. At the foundation is our data infrastructure - built to ingest, store, and retrieve multi-modal vehicle data at unprecedented scale. We create the frameworks for large-scale ETL operations, from data curation and tagging workflows to processing pipelines that transform raw sensor data into high-quality training datasets.
Scale
We operate at massive scale with large GPU clusters and petabytes of autonomous vehicle data. Our systems handle continuous data ingestion at 10+ GB/s rates, ensuring every mile driven contributes to model improvement in real-time. Critical pipelines maintain 99.99% uptime because any downtime directly impacts development velocity for autonomous driving capabilities.
Open-source technologies
Our stack leverages proven distributed computing technologies optimized for autonomous vehicle workloads. Spark handles massive distributed data processing, while Kafka powers real-time streaming pipelines for sensor data. Flyte orchestrates complex multi-step ML workflows, Ray enables distributed training and inference at scale, and Trino provides interactive analytics for rapid data exploration.
Core challenges
We build data lake architecture that seamlessly ingests and stores multi-modal sensor data - cameras, lidar, and radar - from diverse vehicle types worldwide. Our horizontally scalable ETL frameworks transform petabytes of raw sensor data into clean, trainable formats. Most exciting is our cutting-edge research infrastructure enabling both open-loop imitation learning and closed-loop reinforcement learning at scale, with simulation-in-the-loop capabilities.
Data Intelligence

Challenge to solve
Understanding petabyte-scale autonomous vehicle data presents massive challenges: manual labeling is prohibitively expensive, datasets often have incomplete or inconsistent labels, and teams struggle to identify which data will actually improve model performance. Without intelligent curation and automated labeling, ML teams waste resources on redundant data while missing critical edge cases that could prevent field failures.
Solution
Transform raw data into actionable insights through advanced auto labeling and intelligent curation. Build systems that train larger models unconstrained by vehicle compute limits, leveraging latest research techniques across multiple domains - from object detection to HD maps. Own the complete labeling ecosystem from automated pre-labeling to human verification workflows.
- Automated multi-modal labeling across 3D objects, semantics, and HD maps
- Cross-domain model training that scales beyond vehicle compute limits
- Smart data curation that identifies high-value scenarios for model improvement
- Human-in-the-loop workflows that continuously improve labeling accuracy
What is Applied’s Generative AI for Autonomy?
Next Generation Simulation
New reconstruction techniques make it easier than ever to create high fidelity simulation environments from real world data. These tools unlock new levels of environment scale and fidelity that are required for the training and validation of end-to-end autonomous vehicles.
The Problem
Next generation end to end autonomous vehicles require tremendous amounts of real world data for training and validation. Even with hundreds of thousands or millions of hours of driving alone, open loop imitation learning stands as the only choice for forcing AV stacks to copy humans. Closed loop testing and evaluation requires the autonomous vehicle to deviate from the path that expert drivers took in the training corpus, but these new paths render the original sensor inputs and agent behaviors useless.
The Solution
Neural simulation combines novel view synthesis from reconstructed 3D environments and intelligent reactive agent behaviors learned from data in order to train and validate autonomous vehicles in closed loop. When vehicles go off the original path, the reconstructed environment allows for the reprojection of the sensor data into the new frame of reference and intelligent agents react realistically to the new ego behavior.
The Impact
Perfect fidelity digital twins with intelligent agents can act as a virtual playground and test bed for autonomous vehicles. The vehicle can train and validate in closed-loop against real world and bespoke “what-if” scenarios, unlocking reinforcement learning based self-play agents that hold tremendous promise for revolutionizing autonomy.
GenAI for Synthetic Data
The hardest part of developing autonomous vehicles comes in making sure that they can handle specific rare edge cases that may require extensive on-road testing before encountering. Generative models and synthetic data allow for creation of infinite variations of edge cases based on real world data.
The Problem
The real world mostly contains nominal cases for autonomous systems. Even after driving or flying around for hundreds of hours, a customer’s dataset can lack coverage of critical edge cases. Some may try to recreate certain situations on a test-track, but not all conditions can be reproduced faithfully or ethically (think trying to test a kid crossing the street: who would volunteer their own child for safety testing?) Others may recreate situations using crash test dummies or physics-based simulation, but these solutions suffer from a high domain-gap and low scalability.
The Solution
Our team leverages the latest advancements in diffusion-based world models to recreate real world scenes for all domains of autonomy: air, land, and sea. These world models accept multiple inputs as conditioning such as real world images, segmentation masks, etc.

The Impact
Our customers can create highly realistic synthetic data that cover the edge cases their proprietary datasets lack, improving the safety and effectiveness of the underlying autonomy systems.
Automating AV Development
Large multimodal foundation models have changed the way that people complete useful work with machines. Our team significantly accelerates autonomy development by automating many of the tedious or repetitive tasks that take developers away from making significant system improvements.
The Problem
Autonomous system development requires a massive scale of data. As such, many tasks that autonomous vehicle engineers need to complete require significant investment in time and labor. Most programs, for example, need to create tens of thousands of requirements and hundreds of thousands of scenarios to prove that their system passes safety checks. Others have teams of people sifting through thousands of hours of drive logs trying to find scenarios for testing.
The Solution
Our team works to automate many of the critical yet time consuming tasks that our customers face on a daily basis. Customized VLM and LLM models fine-tuned specifically for the autonomy domain underpin an agentic system that can autonomously complete tasks like create simulation scenarios, find data points of interest, and debug simulation scenarios. Multiple agents collaborate with tool-use across our development platform to complete these complex tasks.

The Impact
Autonomous vehicle engineers spend less time on tedious tasks that require manual input or supervision, allowing them to focus more on improving the safety of their systems.
What is Applied’s Research Team?
Focus Areas
E2E research

Multimodal Foundation Models for Autonomy and Robotics
Foundation model with vision, language and action (VLA) modalities facilitates both onboard end-to-end differentiable stacks and offboard simulation and data engine for autonomy and robotics to make them scalable and generalizable.

Reconstruction and World Model for Closed-Loop Simulation
Efficient and scalable 3D/4D reconstruction and world foundation models are the key to scalable closed-loop simulation with autonomy and robotic applications, serving for both evaluation and training of the differentiable stack by leveraging large amounts of real-world and internet data.
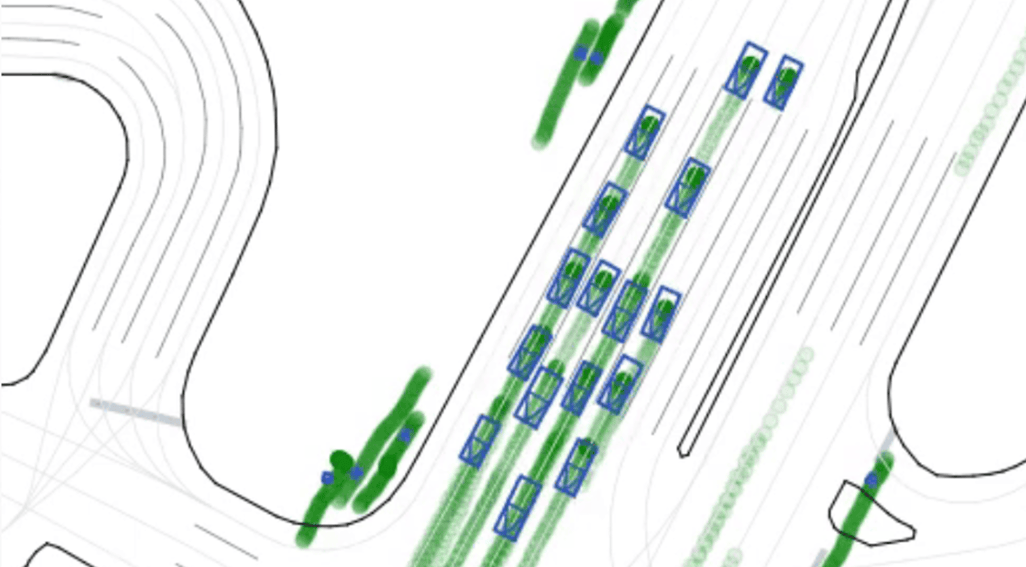
Reinforcement Learning, Reasoning and Post-Training
To robustify and customize the pretrained autonomy and robotic stack, it is crucial to conduct reward-driven post-training in closed loop via reinforcement learning with rewards aligned with human preferences and reasoning enabled.
Our Team

Wei Zhan
Chief Scientist
Affiliations
- UC Berkeley - PhD, Autonomous Driving
- UC Berkeley - Assistant Professional Researcher
- Co-Director of Berkeley Deep Drive
- Co-Director of BAIR Center Humanoid Research

Yihan Hu
Founding Research Scientist
Affiliations
- Horizon Robotics
- Peking University

Akshay Rangesh
Research Engineer
.webp)
.webp)




